September 30, 2025/
Earlier experiments showed how an RL agent can learn basic strategy, adapt to real casino rules, and rediscover card counting...
Can a machine, starting with no knowledge of blackjack, discover the same “basic strategy” that humans use? This first experiment uses a simplified environment and Monte Carlo Control to find out.
The starting point is a one-deck game with only two possible actions: Hit or Stand. The dealer follows the standard rule of hitting until reaching 17 or more. No doubling, splitting, or betting is included yet.
class BlackjackEnv:
def __init__(self):
self.deck, self.player, self.dealer = [], [], []
...This environment reduces blackjack to the essential decision: when to take another card and when to stop.
The agent is trained by playing thousands of full games. At the end of each game, rewards are calculated, and the state–action values (Q-values) are updated. Over time, the agent converges on a strategy that maximizes its long-term return.
def mc_control(num_episodes=200000, epsilon=0.1, gamma=1.0):
Q = defaultdict(lambda: np.zeros(2)) # 0=Hit, 1=Stand
...The learned strategy can be plotted in a grid showing player totals (12–21) versus dealer upcards (1–10).
def extract_policy_grid(policy, usable_ace):
grid = np.zeros((10, 10))
for player in range(12, 22):
for dealer in range(1, 11):
state = (player, dealer, usable_ace)
grid[player-12, dealer-1] = policy.get(state, 0)
return gridThis produces heatmaps where red indicates “Hit” and blue indicates “Stand.”
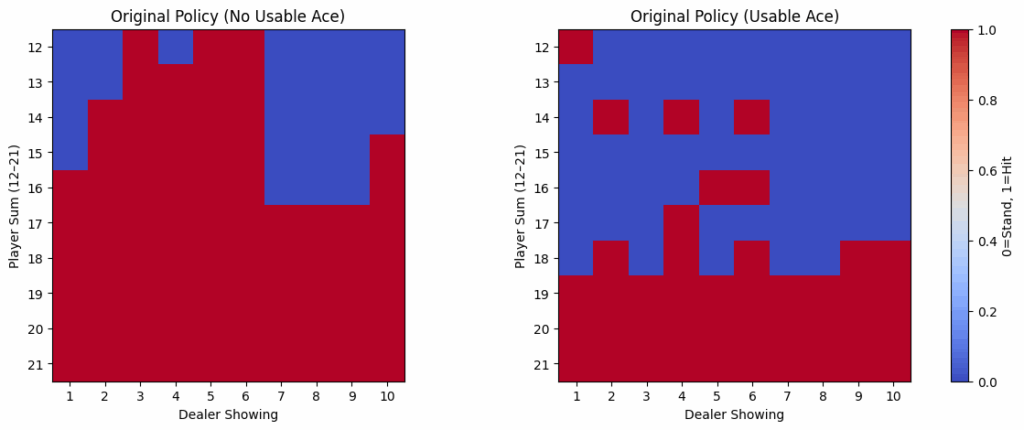
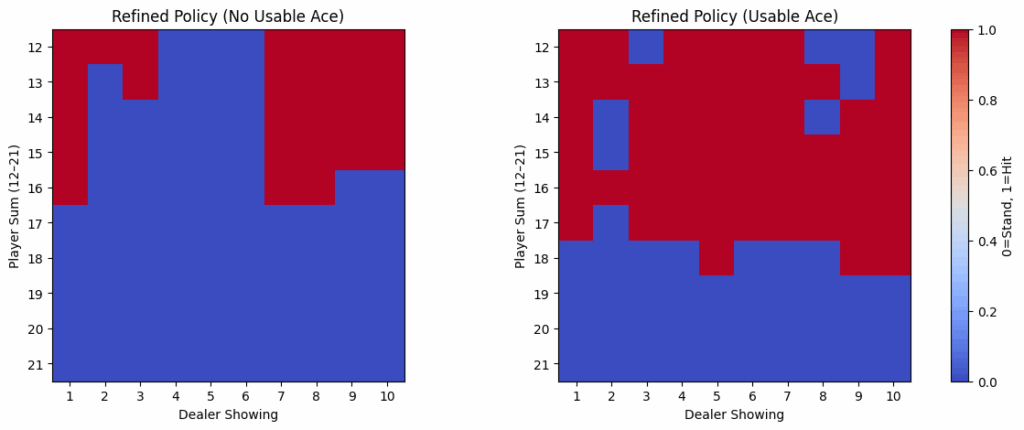
For a more interpretable format, the policy can be summarized in text:
1 2 3 4 5 6 7 8 9 10
Hard 12: H H H H S S H H H H
Hard 13: H S S S S S H H H H
Hard 14: H H H H S S H H H H
...The results closely resemble human basic strategy. The agent has learned:
Monte Carlo RL, given no prior knowledge, converges on strategies that look remarkably similar to basic blackjack charts. Even in this simplified environment, the core principles of optimal play emerge naturally from trial and error.