January 19, 2026/
As part of a larger NLP project focused on analyzing shareholder communications, I needed a clean, consistent corpus of historical...
This stemmed from a project and my approach to the solution. The goal of the project was to create 500 PDFs and email those PDFs out using the Google Suite of products.
I have alot of experience with Google Apps Scripts and have generated PDFs before. However, it is always slightly challenging due to rate limits. As a result, I decided to use Google Colab to create the PDFs. The results are incredibly impressive compared to Google Apps Script. In addition to generating PDFs, I’ll also show how to read in data from a Google Sheets file.
You can read about the email solution to this here.
#import libraries
import gspread
import pandas as pd
from google.colab import auth
from google.auth import default
from google.colab import drive
import pandas as pd
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from fpdf import FPDF
from datetime import date, datetime
import os
#Credtionals
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)
# Open worksheets
sh = gc.open_by_url('Replace with Google Sheets URL')
worksheet_stock_list = sh.worksheet("Stock List")
worksheet_ohlc = sh.worksheet("OHLC")
# Read data into Pandas DataFrames
data_stock_list = worksheet_stock_list.get_all_values()
df_stock_list = pd.DataFrame(data_stock_list[1:], columns=data_stock_list[0])
data_ohlc = worksheet_ohlc.get_all_values()
df_ohlc = pd.DataFrame(data_ohlc[1:], columns=data_ohlc[0])
# Display DataFrames I
df_stock_list.head()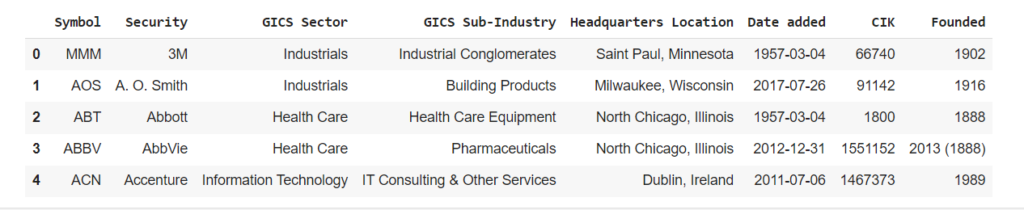
Link to notebook: GitHub
You’ll need to view the notebook for the full code, but here is a portion of the key code
# Mount Google Drive
drive.mount('/content/drive')
def run_process_for_symbol(symbol, df_stock_list, df_ohlc):
today = date.today().strftime("%Y-%m-%d")
# Filter data for the specified symbol (Stock List) and transpose it
# Filter data for the specified symbol (Stock List) and transpose it
stock_list_data = df_stock_list[df_stock_list['Symbol'] == symbol].values.tolist()
# Create a PDF document
pdf = PDF(symbol, today)
pdf.add_page()
# Stock List table (transposed) with adjusted column width and no borders
pdf.chapter_title('Stock List', no_border=True)
column_widths_stock_list = [60, 90] # Adjust these widths based on your data
pdf.chapter_body([df_stock_list.columns.tolist()] + stock_list_data, col_widths=column_widths_stock_list, no_border=True, transpose=True)
# OHLC table with the correct order of columns, transposed, and the first column dropped
pdf.chapter_title('OHLC')
ohlc_data = df_ohlc[df_ohlc['Symbol'] == symbol][['Date', 'Open', 'High', 'Low', 'Close']].values.tolist()
ohlc_column_widths = [25, 35, 25, 25, 25] # Adjusted column widths for OHLC
pdf.chapter_body([['Date', 'Open', 'High', 'Low', 'Close']] + ohlc_data, col_widths=ohlc_column_widths, no_border=False, is_ohlc=True)
# Save PDF to folder
output_folder = 'Foler Path'
# Create the folder if it doesn't exist
os.makedirs(output_folder, exist_ok=True)
pdf_path = os.path.join(output_folder, f'{symbol}_Summary.pdf')
pdf.output(pdf_path)
return pdf_path
def run_process_for_all_symbols(df_stock_list, df_ohlc):
start_time = datetime.now()
# Get unique symbols from the stock list
symbols = df_stock_list['Symbol'].unique()
# Run the process for each symbol
for symbol in symbols:
try:
pdf_path = run_process_for_symbol(symbol, df_stock_list, df_ohlc)
print(f"PDF generated and saved at: {pdf_path}")
except UnicodeEncodeError as e:
print(f"Error generating PDF for symbol {symbol}: {e}")
continue
end_time = datetime.now()
elapsed_time = end_time - start_time
print(f"Total elapsed time: {elapsed_time}")
# Example usage
run_process_for_all_symbols(df_stock_list, df_ohlc)
This portion of the code created 500 PDFs in 5 seconds. This is significantly better than Google Apps Scripts in terms of operational efficiency, but requires more upfront work. This project will be continued with another post here: